
An AI stack is the layered set of technologies, tools, and frameworks that teams use to build, deploy, and operate artificial intelligence systems. Every AI product you use, from a chatbot to a fraud detection engine, runs on some version of an AI stack.
Understanding the AI stack is not just useful for engineers. It is the fastest way to evaluate AI tools without getting overwhelmed, spot gaps in your current setup, and make smarter decisions about where to invest.
This guide breaks down each layer of the AI stack, the tools that belong there, and how to pick the right ones for your use case.
What Is an AI Stack?
An AI stack organises the full lifecycle of AI development into distinct layers. Each layer handles a specific function, from raw data collection to the application your users actually interact with.
A well-designed AI stack allows your team to develop, deploy, and scale AI systems efficiently, and dividing the stack by function helps organisations manage the complexity involved.
Think of it like a traditional tech stack (LAMP, MEAN, JAMstack), but purpose-built for AI workloads. The difference is that AI stacks must handle massive data volumes, computationally intensive model training, and real-time inference at scale.
Similar to technology stacks in software development, an AI stack organises elements into layers that work together to enable efficient and scalable AI implementations.
The 6 Layers of an AI Stack (With Tools)
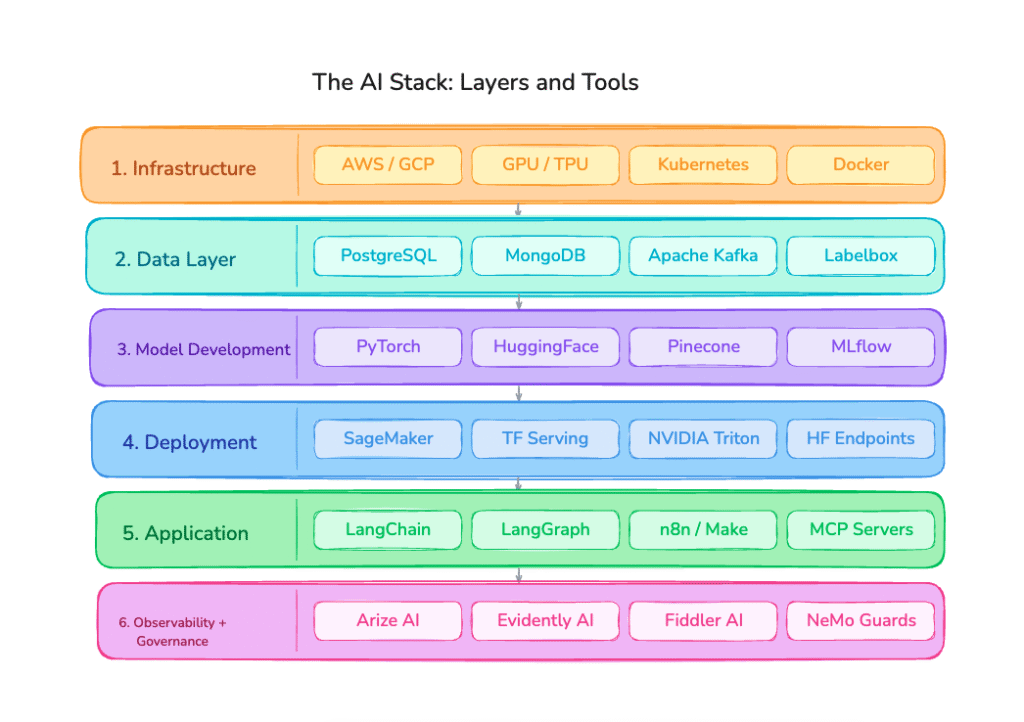
1. Infrastructure Layer: The Foundation
The infrastructure layer provides the compute, storage, and networking resources every other layer depends on. Without it, nothing runs.
Key components include compute resources such as GPUs, TPUs, and CPUs optimised for AI workloads; cloud platforms including AWS, Google Cloud, Microsoft Azure, and IBM Cloud; distributed storage solutions like Amazon S3 and HDFS; and edge compute for real-time inference in low-bandwidth environments.
The infrastructure layer is the raw physical hardware necessary to train and run inference with AI, including GPUs, TPUs, and cloud services like AWS, Azure, and GCP.
Who should care about this layer: primarily ML engineers and DevOps teams. If you are an early-stage team using managed cloud services, most of this is abstracted away. Do not over-engineer what you do not control.
Tool selection tip: evaluate infrastructure tools on cost-per-training-run, autoscaling flexibility, and latency requirements before brand recognition.
2. Data Layer: The Most Underrated Layer
The data layer is the backbone of your AI stack. It is where all the information that fuels your models lives and flows. The quality of your data determines the ceiling of your model. No algorithm compensates for poor or biased training data.
Key components include relational databases like PostgreSQL and MySQL; NoSQL databases like MongoDB and Cassandra; data lakes built on Hadoop or Databricks; ingestion pipelines using Apache Kafka or Fivetran; preprocessing libraries like Pandas and Apache Spark; and data labeling platforms such as Labelbox and Scale AI.
Common mistake: teams rush past this layer to get to model work, then spend months debugging why their model underperforms. Invest here first.
Tool selection tip: match your database to your data type. Structured data suits relational databases. Document or unstructured data suits NoSQL. Mixed workloads benefit from a data lake architecture.
3. Model Development Layer: Where Intelligence Gets Built
This is where algorithms are selected, models are trained, and performance is measured. In 2026, most teams are no longer training from scratch. They are adapting foundation models through fine-tuning, retrieval-augmented generation (RAG), or prompt engineering.
Key components include ML frameworks like TensorFlow, PyTorch, Scikit-learn, and Keras; pretrained model hubs such as Hugging Face, the OpenAI API, and the Anthropic Claude API; experiment tracking tools like MLflow and Weights and Biases; AutoML platforms like Google AutoML and H2O.ai; and vector databases for RAG pipelines including Pinecone, Weaviate, Qdrant, and pgvector.
LLM frameworks like LlamaIndex and LangChain abstract complex development processes involved in creating LLM-powered AI applications. They facilitate connections between vector databases and LLMs, implement prompt engineering techniques, and manage data indexing and ingestion.
Tool selection tip: if you are building a vertical AI product, start with a strong foundation model API before investing in custom training. The economics almost always favour it at the early stage.
4. Model Deployment Layer: Getting Models Into Production
A model that stays in a notebook delivers zero value. Deployment is where machine learning meets software engineering. This layer packages models, exposes them via APIs, and keeps them running reliably at scale.
Key components include containerisation tools like Docker, Kubernetes, and Red Hat OpenShift; model serving frameworks such as TensorFlow Serving and NVIDIA Triton; CI/CD pipelines for ML using DVC and GitHub Actions; and serverless inference endpoints like AWS SageMaker and Hugging Face Inference Endpoints.
The reliability challenge: deployment introduces new failure modes including latency spikes, version drift, and infrastructure outages. Your tooling here needs to handle graceful degradation, not just happy-path success.
Tool selection tip: for early-stage products, managed deployment platforms dramatically reduce operational overhead. Own the infrastructure only when scale demands it.
5. Application Layer: Where AI Becomes a Product
This is where most end users interact with AI. The application layer embeds AI capabilities into workflows, products, and interfaces that drive actual business outcomes.
Key components include AI-native frameworks like LangChain, LlamaIndex, and LangGraph; agent builders such as Voiceflow, Botpress, and n8n; automation platforms like Zapier and Make; MCP servers for tool interoperability; and chatbot and copilot interfaces.
AI-powered platforms now actively make smarter decisions: AI-driven billing platforms predict churn and trigger retention offers, marketing automation tools personalise campaigns at scale, and customer support platforms handle tickets with natural language understanding.
The agentic shift: in 2026, the application layer is increasingly agentic. AI systems are no longer just responding to queries. They are taking multi-step actions, browsing the web, calling APIs, writing code, and orchestrating complex workflows autonomously. Tools that support agent architectures are among the fastest-growing categories in the stack.
Tool selection tip: choose application-layer tools based on composability. Can they connect to your data sources? Can agents call external tools? How well does the abstraction hold as your product scales?
6. Observability and Governance Layers: The Layers You Cannot Skip
These two layers are typically added last. That is almost always a mistake.
Observability gives you visibility into how your models behave in production: latency, accuracy drift, hallucination rates, token costs, and user feedback signals. Governance ensures your AI operates responsibly, covering compliance with GDPR, HIPAA, or the EU AI Act; bias detection; audit trails; and explainability.
Key tools include monitoring platforms like Arize AI, Evidently AI, and Fiddler AI; guardrail tools such as NVIDIA NeMo Guardrails and Guardrails AI; and compliance frameworks built around access control and policy enforcement.
Mature AI stacks evolve via feedback, continuous governance, and modular upgrades. The teams that endure are those that plan for resilience, not just novelty.
Tool selection tip: wire in observability from day one. The cost of debugging production AI issues without telemetry is an order of magnitude higher than setting it up early.
How to Build an AI Stack: A Practical Starting Point
You do not need to build every layer yourself. Most teams assemble their stack from a combination of managed services, open-source tools, and proprietary APIs. Here is a sensible approach by stage.
At the early stage (zero to one product), use managed cloud infrastructure, a strong foundation model API such as Claude, GPT-4o, or Gemini, a hosted vector database, and a lightweight LLM framework like LangChain or LlamaIndex. Focus almost entirely on the application layer, where differentiation lives.
At the growth stage (scaling a product), introduce MLOps tooling, experiment tracking, and proper data pipelines. Add monitoring early. Consider fine-tuning if your use case demands domain-specific accuracy.
At scale (production at volume), invest in infrastructure optimisation, cost management, model compression, and robust governance frameworks. Evaluate whether building versus buying at each layer still makes sense.
Why the AI Stack Framework Matters for Tool Discovery
When you browse AI tools without a stack framework, you end up comparing tools that do not even compete with each other. Or worse, you purchase overlapping capabilities in the same layer without realising it.
The AI stack gives you a mental model to identify gaps in your current setup before they become bottlenecks, avoid redundancy across tools doing the same job, prioritise spend on the layers with the highest ROI for your use case, and communicate clearly across engineering, product, and business teams.
At ToolJunction, every tool in our ai tools directory is categorised by function and use case so you can browse with this kind of clarity. Whether you are looking for the best vector database for a RAG pipeline, a no-code agent builder, or a compliance tool to govern your LLM outputs, you can find and compare tools with the full stack in mind.
Frequently Asked Questions About the AI Stack
What is an LLM?
An LLM, or large language model, is a type of AI model trained on vast amounts of text data to understand and generate human language. LLMs learn statistical patterns across billions of words, which allows them to answer questions, write content, summarise documents, translate languages, and reason through problems.
What is an AI stack in simple terms?
An AI stack is the complete set of tools and technologies used to build, run, and manage AI systems. It is organised into layers, each handling a specific part of the process from data storage to the user-facing application.
What are the main layers of an AI stack?
The core layers are infrastructure, data, model development, model deployment, the application layer, and observability/governance. Different organisations may merge or rename these layers, but the underlying functions are consistent.
What is the difference between an AI stack and an ML stack?
An ML stack typically refers to the subset of the AI stack focused on model development and training. An AI stack is broader, covering everything from infrastructure and data pipelines through to the user-facing application and governance.
What tools are in a generative AI stack?
A generative AI stack typically includes a foundation model provider such as OpenAI, Anthropic, or Google; a vector database like Pinecone or Weaviate; an LLM framework like LangChain or LlamaIndex; a deployment layer like AWS SageMaker or Hugging Face; and a monitoring tool like Arize AI or Evidently AI.
Do I need to build my own AI stack?
Not necessarily. Most early-stage teams assemble their stack from managed services and open-source tools rather than building from scratch. The key is understanding which layer each tool belongs to and how they connect.
Browse AI tools by stack layer on ToolJunction.io — the fastest way to discover, compare, and evaluate the tools shaping the modern AI stack.





Leave a Reply